Sustainability of Linguistic Data
An Ontology of Linguistic Annotation: Word Classes And Morphology
A structured ontology
Our ontology consists of three major components, i.e.:
- a number of domain models which are ontologies that each represent one annotation scheme or tag set,
- the interface model, i.e. the E-EAGLES ontology, which includes reference definitions and thus serves as a terminological backbone by reference to which domain model concepts are defined in a standardised manner, and
- the linking between a domain model and the interface model which is specified apart from both models.
This tripartite structure can be augmented by the optional linking of the interface model with additional upper models. As a result, these upper models can be applied for the formulation of search queries as an alternative to the reference terminology specified in the interface model. Reference definitions retrievable from upper models to domain models are thus mediated by the interface model.
We claim that this modular approach is more flexible as it allows alternative specifications of linking and the inclusion of alternative upper models as well as additional domain models. In present-day annotation technology, it finds a close pendant in the standoff paradigm according to which different levels of annotation and the primary data have to be separated from each other in order to allow for distributed maintenance and concurrent modification. Besides these advantages, it allows for user-specific modifications (such as the specification of alternative upper models) without compromising the ontology as a whole.
The interface model: E-EAGLES
By now, the first version of the E-EAGLES ontology has been implemented using OWL/DL with Protege. Currently, it covers all the obligatory and recommended features from the EAGLES recommendations for morpho-syntactic annotation (Wilson and Leech 1996) plus several categories from non-EAGLES conformant tag sets (e.g. noun classifiers).
The classes in the interface model are retrieved from the EAGLES recommendations in the following way:
- obligatory features (i.e. main word classes, such as noun, verb, etc.) specify top-level categories
- recommended features which specify distinctions that are not purely inflectional specify more fine-grained sub-categories of top-level categories (e.g. the type distinction of nouns: proper nouns vs. common nouns)
- recommended features which specify inflectional distinctions are modelled as properties
As the project data includes a MULTEXT-East-based annotation scheme for Russian, the Uppsala scheme, the relevant definitions of MULTEXT-East have been integrated as well.
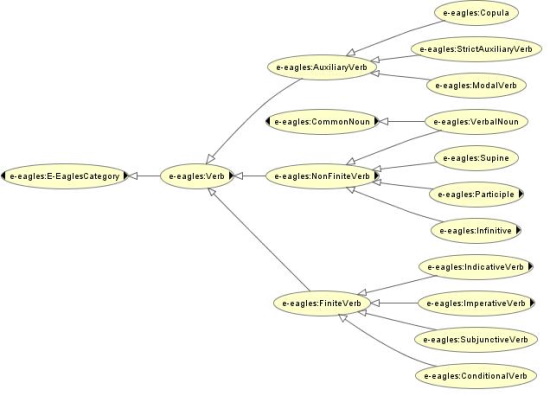
The hierarchy of verbal classes in E-Eagles is given in Fig. 1. Note that compared to the original EAGLES recommendations, AuxillaryVerb and VerbalNoun are redefined in order to account for non-EAGLES conformant tag sets.
Besides this hierarchy of classes, verbs can be further specified by properties such as hasTense, hasAspect, hasPerson, hasNumber, hasVoice, hasSeparability, hasReflexivity and hasGender.
A domain model: Uppsala
Then, domain models are built in a similar manner. Usually, annotation guidelines have a document structure which specifies an otherwise implicitly assumed hierarchical organization, thus, a similar hierarchical structuring of concepts can be achieved.
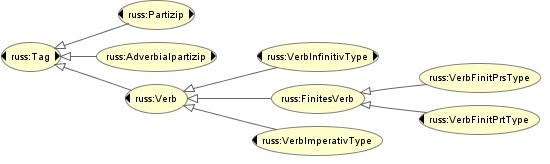
For the tagset applied to the Uppsala corpus, the corresponding structuring of the domain model ontology is given in Fig. 2.
Again, inflectional differentiations are specified by properties in the ontology, i.e. hasGender, hasMood, hasVoice, hasPerson, hasNumber, hasFiniteness, hasAspect and hasTense.
Besides these abstract conceptualizations, concrete tags are integrated as instances into the domain model ontology. Informally, the definition of the Uppsala tag verb_finit_prt_0_sg_neut_refl_pfipf in the ontology can thus be given as:
- verb_finit_prt_0_sg_neut_refl_pfipf ?VerbFinitPrtType and hasTense(past) and hasVoice(reflexive) and hasFiniteness(finite) and hasGender(neuter) and hasMood(indicative) and hasNumber(singular)
Linking domain model and interface model
While domain model and interface model are specified as self-contained ontologies in individual owl files, the linking between both is implemented in a separate file by the rdf:description mechanism.
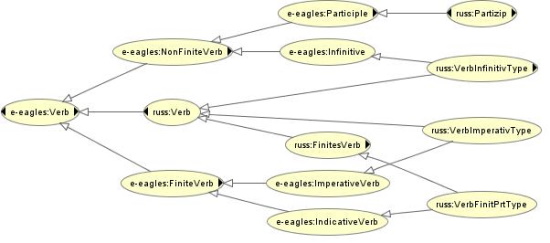
Basically, the linking file contains a specification of domain model classes (not instances) in terms of interface model classes and properties, making up a complex inheritance structure as in Fig. 3 (restricted to subclass relationships). Note that besides the primary classes of word types, also properties and property values from the domain model are specified as sub-properties, instances or sub-classes of properties and classes in the interface model.
A sample query
The linking file imports both the interface model and the corresponding domain model, and thus, it represents an integrating ontology comprising both. If multiple domain models (tag sets) are considered, the corresponding linking files (and the ontologies they import) have to be imported by another file, the so-called master file which represents the ontology as a whole.
In the querying scenario, then, expressions based upon classes and properties in the interface model are expanded according to the inheritance structure within and between interface model and domain models, and then evaluated.
As an example, if we are searching for past-tense reflexive verbs, a specification like Verb and hasTense(Past) and hasVoice(Reflexive) mentions the interface model classes e-eagles:Verb, e-eagles:Past and e-eagles:Reflexive and the properties e-eagles:hasTense and e-eagles:hasVoice. According to the interitance structure depicted in Fig. 3, e-eagles:Verb expands to russ:Verb and further to russ:VerbFinitPrtType, etc. Similarly, e-eagles:hasTense expands to russ:hasTense etc. Thus, amongst other instances, the instance verb_finit_prt_0_sg_neut_refl_pfipf is returned.
The ontology-based query preprocessor, OntoClient, then replaces the ontology-sensitive part of a search query by a disjunction of the tags corresponding to the respective instances, and this modified search query can be further processed by a corpus querying tool.
Alternative Upper Models
The very same mechanism that was used to link domain model concepts with interface model concepts can be employed to establish a linking between the interface model and an additional upper model which provides independent conceptualizations of linguistic terms. Candidates for such upper models are the OntoTag ontologies (an EAGLES-based ontology of linguistic terms with a special application to English and Iberian languages, cf. de Cea 2004), the Data Category Registry currently developed in the context of the Linguistic Annotation Framework (Ide et al. 2004), or GOLD.
As illustration, we are concentrating on GOLD here, as it is a freely available and well-recipied ontological resource with a good coverage of non-European languages. At the moment, any concept in the E-EAGLES ontology is augmented with a reference to the (E-)GOLD ontology.
Nevertheless, it seems reasonable to keep the interface model ontology and the upper model apart. As the development of GOLD is still ongoing, updated versions of GOLD could compromise the linking with the domain models if the domain models are mapped onto the upper model directly. If both upper model and interface model are separated, a modification of the upper model might force an adaption of the linking between upper model and interface model, but not necessarily between the upper model and any other existing domain models.
As the upper model is linked with the interface model in the same way as the interface model and domain model, the corresponding upper model expressions can be used for the formulation of ontology-sensitive corpus queries.
Advantages of the structured approach
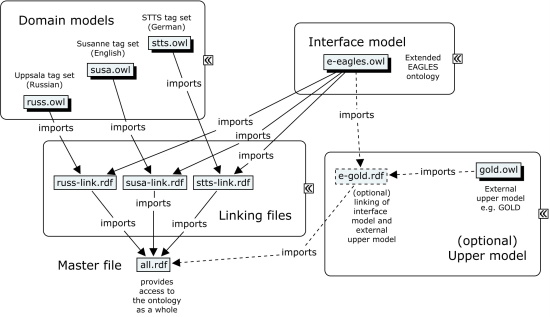
The crucial advantage of a structured modular ontology is its highly flexible and user-adaptive character. As illustrated in Fig. 4, the different components of the ontology are stored separately from each other, and as the import mechanism relies on rdf mechanisms, the concrete location of the corresponding files does not affect the validity of the references. As an example, a user may prefer to use a local variant of a certain domain model, for example because his version of the underlying annotation scheme had slightly different naming conventions than the "official" domain model for this annotation scheme, for a typical example see the numerous variants of STTS which have different tags for pronominal adverbs, e.g. PAV, PROAV and PROP. In this case, only some instances in the domain model have to be renamed, whereas the linking can stay as it is. However, in this case the user has to use a local copy of the linking as well which does not differ from the "official" linking in any other ways than the source of the domain model to be imported.
A user thus may introduce an external upper model, he may redefine the linking between an existing domain model and the interface model without affecting either of them, and he may integrate additional domain models. However, he may not modify the interface model. As it is the central reference point for any linking file, this could affect the linking of other domain models and produce inconsistencies.
This modular structure is thus highly flexible and user-adaptive. A user might even decide to disagree with the conceptualizations in the interface model and develop his very own alternative, but as long as he provides a linking between his conceptualizations and those of the interface model (i.e. he implements his alternative as an upper model in our sense), he does not have to reconsider the linking to all existing domain models.
Especially in the long run, ongoing maintenance of the ontology might require the integration of additional upper models in order to keep touch with the continuous process of terminological evolution, but not the redesign of the interface model. The effort to have an intelligible interface to the resources associated with certain domain models is thus reduced to the task to maintain the linking between interface model and upper model.
Our implementation provides a modular view on the ontology. The ontology consists of three principal components, the upper model presenting a central registry of relevant terminology, several domain models, each covering the tags of one specific POS tag set, and the respective linking between upper model and domain model, which are each stored in independent files.
To access to the ontology as a whole, an additional "master file" is necessary which provides unified access to the interface model, the upper model, the domain models and the linking between them from separate OWL/RDF files. As the interface model does not specify the ultimate repository of linguistic terminology, additional upper models can be integrated in this master file. As a user can define own conceptualisations by this mechanism, the main benefit of our approach and the development of the interface model lies in the fact that it is no longer necessary to consider every tag set by its own. Instead, later refinements are mediated by the upper model, thus the most important achievement is that the interface model provides a unified access to different tag sets for both querying and redefinition.
Besides its function in tag set neutral corpus queries and in the theory-neutral definition of language-, project- or task-specific annotation schemes by linking the corresponding domain model with the interface model, the ontology can be practically applied in the design of tag set neutral corpus processing scripts (Krasavina et al. 2007), or, more generally, in the field of Semantic Web applications and ontology-based annotation (for a similar approach on a more restricted set of languages cf. de Cea et al. 2004).
Example ontology
An example can be downloaded here!
Ontology list
Papers and Publications
| Author | Title | Published in | Year |
|---|---|---|---|
| Chiarcos, C. | An Ontology of Linguistic Annotation: Word Classes and Morphology. | In Proceedings DIALOG 2007, Bekasovo/Moscow, May 30 – June 3, 2007, p.630-637. | 2007 |
| Lehmberg, T., Chiarcos, C., Hinrichs, E., Rehm, G. & Witt, A. | Collecting Legally Relevant Metadata by Means of a Decision-Tree-Based Questionnaire System. | In Proceedings of Digital Humanities 2007, University of Illinois, Urbana-Champaign, USA. | 2007 |
| Lehmberg, T., Chiarcos, C., Rehm, G. & Witt, A. | Rechtsfragen bei der Nutzung und Weitergabe linguistischer Daten. | In Georg Rehm, Andreas Witt, Lothar Lemnitzer (eds.), Data Structures for Linguistic Resources and Applications. Proceedings of the Biennial GLDV Conference 2007, Tübingen/Germany, April 11-13, 2007. Gunter Narr: Tübingen, p.93-102. | 2007 |
| Krasavina, O., Chiarcos, C. & Zalmanov, D. | Aspects of topicality in the use of demonstrative expressions in German, English and Russian. | In António Branco, Tony McEnery, Ruslan Mitkov and Fátima Silva (Eds.), Proc. 6th Discourse Anaphora and Anaphor Resolution Colloquium (DAARC-2007), Lagos (Algarve)/Portugal, March 29-30, 2007, p.53-58. | 2007 |
| Chiarcos, C. | Semimanuelle Generierung und Auswertung von Alternativentexten. | In Hardarik Blühdorn, Eva Breindl, Ulrich Waßner (Eds.), Text – Verstehen. Grammatik und darüber hinaus. Institut für Deutsche Sprache. Jahrbuch 2005. De Gruyter, Berlin, New York, 2006, p.406-410. | 2006 |
| Chiarcos, C. | Sustainability of Linguistic Data. | In Proceedings of the 1st International Conference of SFB632: Information structure between linguistic theory and empirical methods. June 6-8, 2006, Potsdam, p. 161-166. | 2006 |
| Chiarcos, C. | Avoiding Data Graveyards: Deriving an Ontology for Accessing Heterogeneous Data Collections. | In Proceedings of the International Workshop „Ontologies in Text Technology (OTT'06). Approaches to Extract Semantic Knowledge from Syntactic Information“. September 28-29, 2006, Osnabrück, Germany, p.113-118. | 2006 |
| Chiarcos, C. | An Ontology for Heterogeneous Data Collections. | In Proceedings of the Int. Conference “Corpus Linguistics 2006”, October 10–14, 2006, St.-Petersburg, St.-Petersburg University Press, p. 373-380. | 2006 |
| Schmidt, Th., Chiarcos, C., Lehmberg, T., Rehm, G., Witt, A. & Hinrichs, E. | Avoiding Data Graveyards: From Heterogeneous Data Collected in Multiple Research Projects to Sustainable Linguistic Resources. | In Proceedings of the E-MELD 2006 Workshop on Digital Language Documentation: Tools and Standards – The State of the Art, Michigan State University in East Lansing, Michigan, June 2006. | 2006 |